Release Summary 25.08 | Apr 17, 2025
The following key features and improvements, along with bug fixes, have been released in Algonomy CXP products in the release version 25.08.
Enterprise Dashboard
Tabbed Recommendations Dynamic Experiences Template
A new Dynamic Experiences template called “Tabbed Recommendations” has been introduced to help shoppers easily discover relevant products by organizing recommendations under category-based tabs.
This template dynamically populates category tabs using the affinityScoresByConfig API, ordered by descending user affinity scores. Upon selecting a tab, it triggers a recsForPlacements API call to fetch relevant products for the corresponding category. The design supports up to 5 categories and is optimized for mobile.
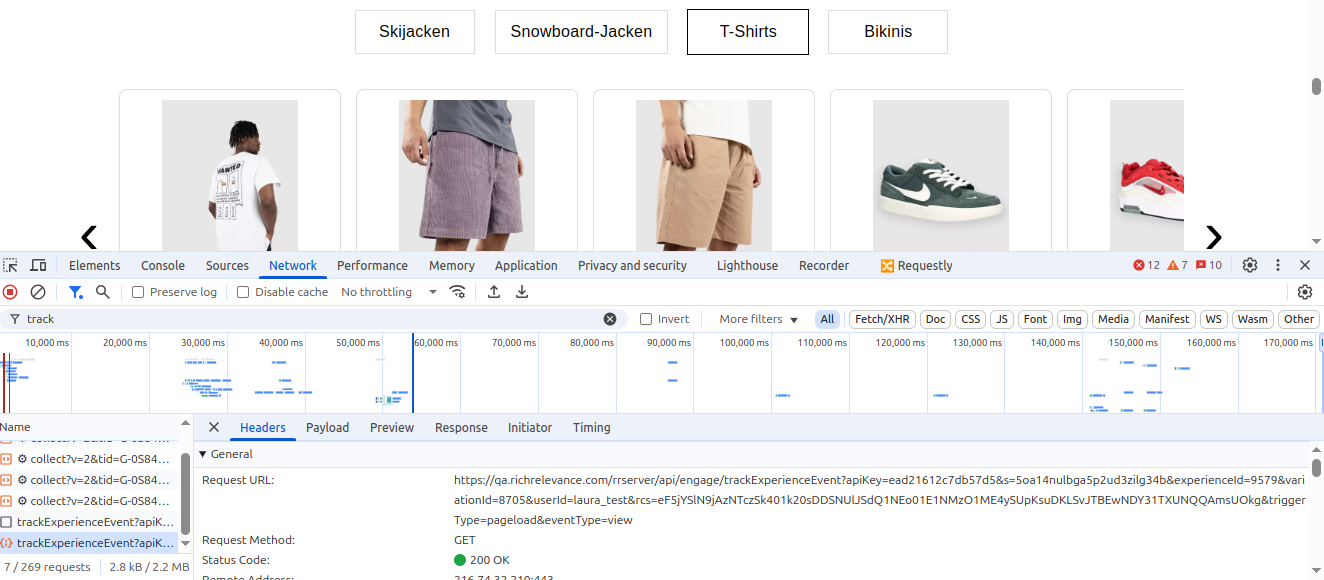
Jira: ENG-29832
Content Test Drive Preview Now Available
A new “Content Test Drive” page has been introduced to help digital optimization managers preview and validate content placements before deployment. The interface follows the same design as Recs Test Drive, allowing users to select multiple content placements from a single page type and preview content served via the Personalize API.
Users can configure optional parameters like user ID, region, channel, tag filters, tag refinements, and blocked contents. The test drive supports both production and integration environments, with support for advanced logic in tag-based filtering and refinement. The results section displays the rendered content, helping teams fine-tune and validate their content campaigns with ease.
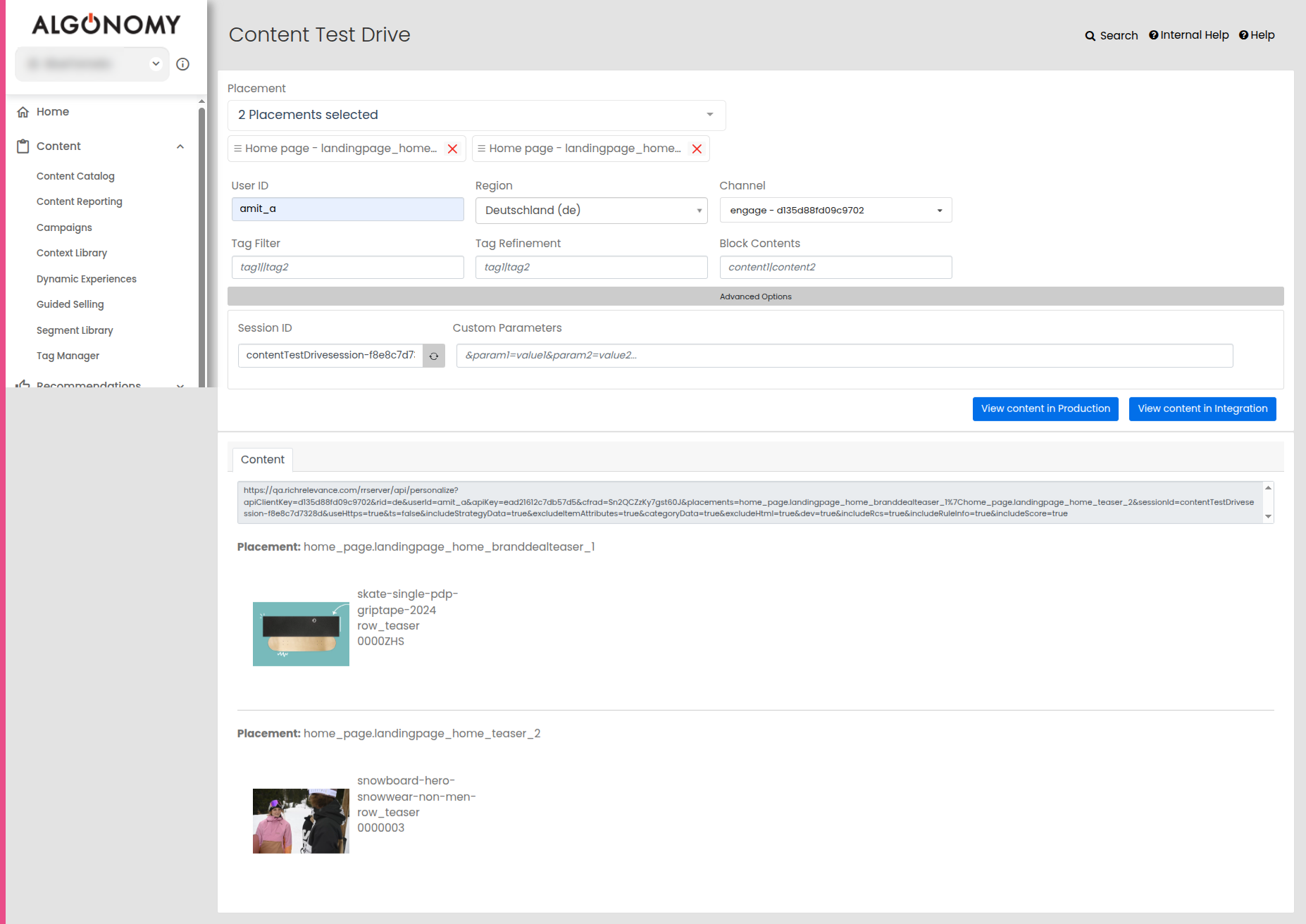
Jira: ENG-28661
MVT Reporting Enhancement – Filter by Products Shown Social Proof
A new filter option has been added to the Social Proof MVT report that allows Merchandisers to view performance metrics based only on the products where social proof messaging was actually shown. This enhancement enables a more accurate comparison between control and treatment by focusing on visits where social proof was visible, providing a clearer picture of its impact.
The “Filter by products shown social proof message” option is available only for Social Proof MVT test types. Once enabled, it filters the report to include visits where the treatment group (Social Proof ON) displayed the messaging, allowing for a true apples-to-apples comparison. Additional filters can still be applied, and all existing metrics, including lift and confidence levels, remain visible.
Jira: ENG-29980
Social Proof
Social Proof Optimization – Conditional Prediction API Call Based on Variation Setting
The Social Proof Output Response API has been enhanced to invoke the Prediction API only when optimization is explicitly enabled at the variation level. Previously, once optimization was enabled at the site level, all variations defaulted to optimized message delivery, without considering the variation-level toggle.
With this improvement, optimization will now trigger only for variations where it is enabled via the UI, provided the site-level configuration allows it. Variations without this setting will continue to serve non-optimized messages. This change provides finer control for A/B testing different optimization strategies and gives clients the flexibility to selectively apply optimization.
Jira: ENG-29766
Find
Find Zero Search Results Report: UI Improvements
The Zero Search Results report has been updated for a better user experience. The tab styling now aligns with the design used in the Rec Type Analysis report, offering a cleaner and more intuitive look. Additionally, the title "Zero Results (without facets)" has been simplified to "Zero Search Results" for clarity.
Jira: ENG-30039
Recommend
Refinements Enhancement – Wildcard Support for Partial Attribute Matches
Refinement filters now support wildcard matching, allowing more flexible filtering of hierarchical product attributes. This enhancement is particularly useful in use cases where a single attribute value represents compatibility with a range of variations. For instance, a refinement value like /Brand/Model/Variant/* will match all values beginning with that pattern, such as /Brand/Model/Variant/Option1 or /Brand/Model/Variant/Option1/SubOption.
This improvement enables reduced catalog complexity while maintaining precise filtering logic. All existing refinement features—including AND/OR conditions and fallback logic—remain fully supported.
Jira: ENG-29981
Recommend, Ensemble AI
Ensemble AI : Real-Time Preference Feedback Integration
Ensemble AI now incorporates shopper preferences sent in the current request into the real-time generation of ensembles. Previously, only preferences stored in the User Profile Service (UPS) were considered. With this enhancement, both existing preferences from UPS and new feedback from the current request are combined to generate more relevant, personalized ensemble results.
This improvement ensures that ensemble recommendations adapt instantly to shopper feedback, even during the same session, aligning behavior with how item views are handled in Recommend.
Jira: ENG-29659
Other Feature Enhancements
The following feature enhancements and upgrades have been made in the release version 25.08.
|
Jira # |
Module/Title |
Summary |
General Availability |
|---|---|---|---|
|
Science: Query Enrichment Mapping Flow for Manual Entries |
A new flow has been created to populate client-provided manual query enrichment mappings into the find.query_enrichment_mappings PSQL table. The flow captures fields such as query, enrichment terms, language, type, source, and timestamps, enabling structured storage and future retrieval. |
17-Apr-25 |
|
|
Science: PSQL Table for Query Enrichment Configuration |
A new PSQL table find.query_enrichment_config has been created to store site-level query enrichment configurations. This includes fields such as language, suffixes, and synonym mapping preferences in JSON format. The table supports scalable and customizable enrichment behavior for each site. |
17-Apr-25 |
|
|
Science: Find Query Enrichment Pipeline Enhancement |
The enrich_query() function has been integrated just before the Find query embedding stage. This enhancement ensures that enrichment is applied using site-specific configurations from the PSQL tables. Additionally, the output file format has been updated to include a third column—[enriched_document]—capturing the enriched query alongside the original document and its embedding. |
17-Apr-25 |
|
|
Science: Ensemble AI Model Build: Performance Optimizations |
Several improvements have been made to optimize the Ensemble AI model build process. These include better Spark task distribution, reduced network IO, and simplified logic to minimize processor time. Key enhancements include repartitioning data for even distribution, using data broadcasting, caching, and removing redundant computations. These updates ensure faster, more efficient model execution and retain older models when a new build fails. |
17-Apr-25 |
|
|
Science: Ensemble AI: Shopper Feedback Score Calculation |
A feedback score is now computed for each ensemble to enhance personalization based on shopper interactions such as "more like this" or "less like this." The score is calculated using default attributes including brand and total price bucket, which is based on the combined prices of products within the ensemble. A decay-based formula is applied using multipliers stored in the user profile system (UPS) to reflect recent shopper preferences. The feedback score helps identify ensembles that align more closely with a shopper’s interests and will be used to influence future ensemble rankings during recommendation delivery. |
17-Apr-25 |
|
|
Social Proof: Social Proof Messaging API: Force Variation ID
|
The Social Proof Messaging API now supports a force_varId parameter, allowing you to always play a specific variation’s messaging—bypassing traffic allocation rules. This is especially useful for running external A/B tests using tools like Adobe. If optimization is enabled, the forced variation will return optimized messages as well. |
17-Apr-25 |
|
|
Find: Monitoring: Catalog Vector Fields in Solr |
A new hourly monitor script now checks for catalog vector fields (vector_1024_*) in Solr for configured sites. If any fields are missing, it automatically triggers a Slack alert. This ensures timely detection of vector indexing issues. |
17-Apr-25 |
|
|
Add Enriched Query Field to Query Vector PDC |
To improve debugging and transparency in embedding generation, a new enriched_query field has been added to the default property definition collection (PDC) for queryvector. This ensures that the exact enriched input text used for vector generation is stored and visible in Solr's MetaStore. New PDCs will now include this field by default. |
17-Apr-25 |
|
|
Query Vector Job Updated to Push Enriched Query |
The Query Vector job has been enhanced to include the enriched query text alongside the query vector during streaming ingestion. This allows visibility into the exact enriched input used for embedding, aiding in debugging and ensuring enriched queries are properly captured in Solr's MetaStore Collection. |
17-Apr-25 |
|
|
Patch Existing Query Vector PDCs to Support Enriched Query |
The existing Query Vector Property Definition Collections (PDCs) have been patched to include the enriched_query field. This ensures enriched queries are ingested without requiring new MetaStore snapshots, aligning with recent updates to query vector ingestion. |
17-Apr-25 |
|
|
Standardized Index and Primary Key Setup for Catalog Embedding Tables |
A changescript has been added to update the primary key and indexes for find_catalog_embedding tables across all sites, including those where hybrid search was not previously enabled. |
17-Apr-25 |
|
|
SFI Compatibility Check for Streaming Catalog Update |
Sanity and regression tests were run on streaming catalog v1.26.0 to verify the impact of recent site partition logic changes. No issues were found with SFI consuming from the streaming.engine.out topic. |
17-Apr-25 |
|
|
Recommend: Consistent Rule Application on Backfill Strategies |
Recommendation restriction rules, such as attribute diversity, are now applied uniformly across both base and backfill strategies. This ensures consistent filtering of products, regardless of the strategy source. |
17-Apr-25 |
|
|
Accurate Timing for Ebclient Search Service |
The Ebclient timer has been updated to measure only the actual search service time, excluding any preprocessing overhead. This ensures more precise monitoring of search performance. |
17-Apr-25 |
|
|
Enterprise Dashboard: Update Support Portal Link in Dashboard-Dynamic |
The Support customer portal link in the RR Portal has been updated in the header.jsp of the dashboard-dynamic. |
17-Apr-25 |
|
|
Externalized Kafka Partition Allocation to Postgres |
The site partition allocation logic for streaming has been moved from code to a Postgres configuration table. This allows easier assignment of dedicated Kafka partitions to sites without requiring code changes. Existing partition logic and hash-based allocation for shared partitions remain unchanged. |
17-Apr-25 |
|
|
Store Customer-Submitted Queries in HDFS for Embedding
|
To improve coverage in the query embedding process, all customer-submitted queries are now stored in the HDFS path /model_build/query_vector/queries/<site_id>/. This ensures that even if certain queries don’t appear in recent tracking data, they will still be included in the query vector embedding job. |
17-Apr-25 |
Bug and Support Fixes
The following issues have been fixed in the release version 25.08.
|
Jira # |
Module/Title |
Summary |
General Availability |
|---|---|---|---|
|
Streaming-recommend: Improved Identity Lookup in Streaming Itemstore Consumer
|
Fixed an issue where association identities weren’t retrieved locally due to separate MapDB instances, causing unnecessary identity service calls and slowing ingestion. Local lookups now work as expected, improving performance. |
17-Apr-25 |
|
|
Enterprise Dashboard: Seed Validation Error in Configurable Strategies for Top Sellers |
Resolved an issue where users encountered a "no seed specified" error in Configurable Strategies, even after switching to a model like Top Sellers that doesn't require a seed. Users can now switch models and view results without being blocked by incorrect validation. |
17-Apr-25 |
|
|
Enterprise Dashboard: Variables Section Display Issue in Comparison Placement Template |
Fixed an issue where the Variables sections in the Comparison placement template were not displaying correctly, preventing users from expanding or collapsing them. |
17-Apr-25 |
|
|
Find: Package Upload Failure on Fresh Solr Setup |
Resolved a NullPointerException that occurred during fresh Solr installations where SFI and Find Deployer failed to upload packages to the Solr package store. The issue was caused by malformed JSON handling in the package helper logic. |
17-Apr-25 |
|
|
Recommend: Localization Fallback to Default Region |
The fallback mechanism to return default region (English) is now correctly applied across all relevant areas. |
17-Apr-25 |
|
|
Build Failures Due to Missing language_tag Column in find_catalog_embeddings
|
Fixed an issue causing multiple build and PR failures related to missing language_tag column in the find_catalog_embeddings table. The failure occurred during test setups where the altered primary key and index creation expected this column to exist. The fix ensures that the column is added if missing, allowing builds to proceed without errors. |
17-Apr-25 |
|
|
Find: Disable Reranking When Sort Order Is Not by Score |
Resolved an issue where reranking was incorrectly applied even when users selected a sort order other than relevance (score descending), such as price low to high. This caused the results to appear out of order. Reranking is now skipped unless the sort order is explicitly set to score descending. |
17-Apr-25 |
|
|
Boosting Rules Not Fully Applied |
Fixed an issue where not all boosting rules were being applied during search execution. Although rules were saved successfully, only a subset were reflected in the Solr query. Now, all configured boost rules are correctly incorporated into the search query as expected. |
17-Apr-25 |
|
|
Recommend: TopViews Model Returning Low-View Products
|
Resolved an issue in the TopViews model where the results included products with unusually low view counts, inconsistent with expectations and the TopProducts model. This was affecting both the model browser and configurable strategies. The underlying cause has been addressed, and the model now correctly reflects product popularity based on recent view data. |
17-Apr-25 |